In lots of web apps you need to count something. Availability of products, number of login attempts, visitors on a page and so on.
I'll show multiple ways to implement this, all of them are based on the following (somewhat fictional) requirements.
You have to implement a web-shop which lists products. Every product has an availability which must not go below 0 (we only sell goods if we have them on stock). There must be a method #take which handles the decrement and returns itself. If anything goes wrong (i.e. out of stock) then an exception must be raised.
The samples only deal with decrementing a counter. But of course incrementing is the same as decrementing with a negative amount. All the code is available in a git repository and each way is implemented in its own XYZProduct class. I ran the samples on Postgres and one implementation is Postgres specific but should be easy to adapt for other RDBMS.
Change value of attribute and save
The first thing that might come to your mind could look like this:
class SimpleProduct > ActiveRecord::Base
validates :available, numericality: {greater_than_or_equal_to: 0}
def take!
self.available -= 1
save!
self
end
end
The #take! method just decrements the counter and calls save!. This might throw an ActiveRecord::RecordInvalid exception if the validation is violated (negative availability). Simple enough and it works as expected. But only as long as there are not multiple clients ordering the same product at the same time!
Consider the following example which explains what can go wrong:
p = SimpleProduct.create!(available: 1)
p1 = SimpleProduct.find(p.id)
p2 = SimpleProduct.find(p.id)
p1.take!
p2.take!
puts p.reload.available
p1 and p2available does not go below 0 is executed against the current state of the instance and therefore p2 uses stale data for the validation.
The same holds true for increment! and decrement!
So how do deal with this problem? We somehow need to lock the record in order to prevent concurrent updates. One simple way to to achieve this is by using optimistic locking.
Optimistic Locking
By adding a lock_version column, which gets incremented whenever the record is saved, we know if somebody else has changed the counter. In such cases ActiveRecord::StaleObjectError is thrown. Then we need to reload the record and try again. Rails allows to specify the lock column name. See Locking::Optimistic for details.
The following snippet should explain how optimistic locking works:
p = OptimisticProduct.create(available: 10)
p1 = OptimisticProduct.find(p.id)
p2 = OptimisticProduct.find(p.id)
p1.take!
p2.take!
by reloading p2 before we call #take! the code will work as expected.
p2.reload.take!
Of course we can not sprinkle reload calls throughout our code and hope that the instance is not stale anymore. One way to solve this is to use a begin/rescue block with retry.
begin
product.take!
rescue ActiveRecord::StaleObjectError
product.reload
retry
end
When StaleObjectError is rescued then the whole block is retried. This only makes sense if the product is reloaded from the DB so we get the latest lock_version. I do not really like this way of retrying because it boils down to a loop without a defined exit condition. Also this might lead to many retries when a lot of people are buying the same product.
Pessimistic Locking
ActiveRecord also supports pessimistic locking, which is implemented as row-level locking using a SELECT FOR UPDATE clause. Other, DB specific, lock clauses can be specified if required. Implementation could look as follows:
class PessimisticProduct > ActiveRecord::Base
validates :available, numericality: {greater_than_or_equal_to: 0}
def take!
with_lock do
self.available -= 1
save!
end
self
end
end
The #with_lock method accepts a block which is executed within a transaction and the instance is reloaded with lock: true. Since the instance is reloaded the validation also works as expected. Nice and clean.
You can check the behaviour of #with_lock by running following code in two different Rails consoles (replace Thing with one of your AR classes):
thing = Thing.find(1)
thing.with_lock do
puts "inside lock"
sleep 10
end
You will notice that in the first console the "inside lock" output will appear right away whereas in the second console it only appears after the first call wakes up from sleep and exits the with_lock block.
DB specific, custom SQL
If you are ready to explore some more advanced features of your RDBMS you could write it with a check constraint for the validation and make sure that the decrement is executed on the DB itself. The constraint can be added in a migration like this:
class AddCheckToDbCheckProducts > ActiveRecord::Migration
def up
execute "alter table db_check_products add constraint check_available \
check (available IS NULL OR available >= 0)"
end
def down
execute 'alter table db_check_products drop constraint check_available'
end
end
This makes sure that the counter can not go below zero. Nice. But we also need to decrement the counter on the DB:
class DbCheckProduct > ActiveRecord::Base
def take!
sql = "UPDATE #{self.class.table_name} SET available = available - 1 WHERE id = #{self.id} AND available IS NOT NULL RETURNING available"
result_set = self.class.connection.execute(sql)
if result_set.ntuples == 1
self.available = result_set.getvalue(0, 0).to_i
end
self
end
end
Should the check constraint be violated, then ActiveRecord::StatementInvalid is raised. I would have expected a somewhat more descriptive exception but it does the trick.
This again works as expected but compared to the with_lock version includes more code, DB specific SQL statements and could be vulnerable to SQL injection (through a modified value of id). It also bypasses validations, callbacks and does not modify the updated_at timestamp.
Performance
Yes I know. Microbenchmark. Still I measured the time for each implementation in various configurations.
1 thread, 1'000 products available, take 1'000 products
| Implementation |
Duration [s] |
Correct? |
SimpleProduct |
1.71 |
YES |
OptimisticProduct |
1.87 |
YES |
PessimisticProduct |
2.16 |
YES |
DbCheckProduct |
0.91 |
YES |
1 thread, 1'000 products available, take 1'500 products
| Implementation |
Duration [s] |
Correct? |
SimpleProduct |
2.52 |
YES |
OptimisticProduct |
2.81 |
YES |
PessimisticProduct |
3.25 |
YES |
DbCheckProduct |
1.42 |
YES |
10 threads, 1'000 products available, take 1'000 products
| Implementation |
Duration [s] |
Correct? |
SimpleProduct |
1.51 |
NO |
OptimisticProduct |
15.86 |
YES |
PessimisticProduct |
1.87 |
YES |
DbCheckProduct |
0.61 |
YES |
10 threads, 1'000 products available, take 1'500 products
| Implementation |
Duration [s] |
Correct? |
SimpleProduct |
2.19 |
NO |
OptimisticProduct |
18.94 |
YES |
PessimisticProduct |
2.74 |
YES |
DbCheckProduct |
1.23 |
YES |
Some interesting things to learn from these results:
SimpleProduct gives wrong results for concurrent situations, as explained above.OptimisticProduct has some problems to scale with multiple threads. This makes sense as there is retry involved when concurrent updates occur.DbCheckProduct is the fastest implementation which seems reasonable as there is no locking involvedDbCheckProduct and PessimisticProduct can both profit in a concurrent setup
Summary
Depending on your requirements the simplest way could already work and be good enough. If you have more specific requirements (i.e. validations, concurrency) then I'd suggest to go with the pessimistic locking as it is quite easy to implement and well tested (compared to my check constraint implementation of #take!). It is important to release a pessimistic lock ASAP as it blocks other clients from accessing the data.
Ever wondered what the load order of the various configuration files of Rails is?
In Rails the (more or less) common places to configure your app are:
- application.rb
- config/environments/*.rb
- config/initializers/*.rb
- after_initialize callbacks (in application.rb or in environment specific files)
Since there is multiple points where you can add the configuration the order in which those configurations are applied is important. E.g. it might happen that you set a value in one place and it gets reverted from another config file. This is the order that get's applied, tested in Rails 4.2
- application.rb
- environment specific config file in config/environments/*.rb
- initializers, they are loaded in alphabetical order
- after_initialize callbacks, in the order they have been added
The (currently) last part of my encoding hell series. To finish up I'll show some samples.
force_encoding and encode
Ruby is smart enough to not encode a string if it is already in the target encoding. This might not be what you want if you have data which has been encoded wrongly in the first place. You can use force_encoding in such cases:
data = "\xF6\xE4\xFC"
p data.encoding
p data.encode('utf-8')
p data.force_encoding('iso-8859-1').encode('utf-8')
transcoding
Data read from a file is expected to be in UTF-8 by default. You can change that using the encoding option. This will lead to Strings that are encoded in something non-UTF-8 though. Ruby offers an easy way to transcode, so you only will have to deal with UTF-8 Strings
data = File.read('file.txt')
puts data.encoding
data = File.read('file.txt', encoding: 'iso-8859-1')
puts data.encoding
data = File.read('file.txt', encoding: 'iso-8859-1:utf-8')
puts data.encoding
String concatenation
This works as long as both Strings are in the same or in a compatible encoding. This can happen in places where you don't expect it. For example when writing a CSV file or just print out some log information.
utf = "öäü"
iso_1 = utf.encode('iso-8859-1')
iso_2 = "oau".encode('iso-8859-1')
ascii = "oau".encode('ascii')
puts utf + utf
puts utf + iso_1
puts utf + iso_2
puts utf + ascii
puts and p
Ruby calls #inspect when passing an object to p. This leads to some interesting behaviour when printing out Strings of different encodings.
p "öäü".encode('iso-8859-1')
puts "öäü".encode('iso-8859-1')
puts "öäü".encode('iso-8859-1').inspect
How does Ruby deal with encoding? Here are some important parts.
There are multiple encoding settings and multiple ways they are initialized. And of course this differs depending on the Ruby version used. Most of this has been found out by trial and error as I could not find a concise documentation of all those values. Corrections are welcome.
__ENCODING__
This is the encoding used for created strings. The locale is determined by the encoding of the source file (defaulted to US-ASCII in 1.9, now defaults to UTF-8) which can be changed with an encoding comment on the first line (e.g. #encoding: CP1252)
Encoding.default_internal
The default internal encoding. Strings read from files, CSV, ARGV and some more are transcoded to this encoding if it is not nil. According to the docs the value can be changed using the -E option. This did not work for me though, neither with 1.9.3 nor with 2.2.0.
Encoding.default_external
Data written to disk will be transcoded to this encoding by default. It is initialized by
-E OptionLANG environment setting
And it seems to default to ASCII-8BIT
String#encoding
Returns the current encoding of the String. This is usually the __ENCODING__ for created strings.
String#force_encoding
Changes the encoding. Does not re-encode the string but changes what #encoding will return.
String#encode
Re-encode the string in the new encoding. Does not change the string if it is already in the target encoding. You can pass transcode options.
I18n.transliterate
Replaces non US-ASCII characters with an US-ASCII approximation.
In the next part I'll show some example code. It should be online soon.
If you ended up reading this, then you know what i am talking about. It's this garbled up text. That umlaut which got lost. Those diacritical marks that don't show up. And then first you blame the accent-grave-french, the umlaut-germans, the diacritic-czechs and so on (not even mentioning chinese/japanese/...languages) .
Why can't we all live with ASCII. Surely 8 bit ought to be enough for everyone;-)
So this is the first post on my encoding hell. I plan to follow up with more posts on this topic.

The situation
At Simplificator we recently worked on a ETL application. This application loads data from various sources (databases, files, services, e-mails), processes it (merge, filter, extract, enrich) and stores in various destinations (databases and files). This application is a central tool for data exchange between multiple companies. Data exchanged ranges from list of employees to warranty coverage of refrigerators. Not all sources are under our control and neither are the targets.
And this is where the problems started. Some sources are delivering UTF-8, some are using CP-1252, some are in ISO-8859-1 (a.k.a Latin-1). Some destinations are expecting ISO-8859-1 and some are expecting UTF-8.
ISO 8859-1 (ISO/IEC 8859-1) actually only specifies the printable characters, ISO-8859-1 defined by IANA (notice the dash) adds some control codes.
The problem
While in most programming languages it is easy to change the encoding of a string this sometimes includes more troubles than visible at first sight. Those encodings can contain from 256 to more than 1'000'000 code points. In other words: UTF-8 is a superset of CP-1252 and ISO 8859-1. Going from those 8 bit encodings to a (variable length) 4 byte encoding is always possible while for the other way it depends on the content. If an UTF-8 String contains characters which can not be encoded in 8 bit then you have a problem. Say hi to your new best friend the Encoding::UndefinedConversionError (or whatever your programming language of choice throws at you in such cases).
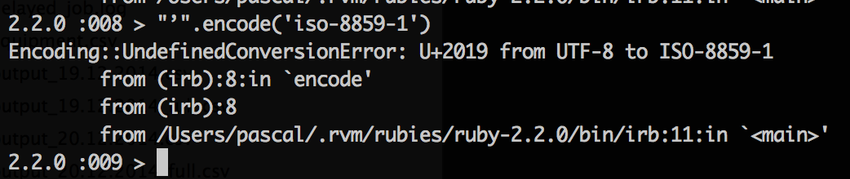
The solutions
There are two solutions for this. Both are relatively easy. And both might cause trouble by the consumers of your output. As mentioned the problem only shows when the content (or parts of it) are not covered by the destination encoding. CP-1252, ISO 8859-1 and UTF-8 share characters between 0020 and 007E (ASCII, without some control codes). As long as your content is within that range there is actually nothing to change when changing the encoding. But if your content lies outside this range then you either have to:
- Use UTF-8 for your output everywhere: Going from UTF-8/CP1252/ISO-8859-1 to UTF-8 is easy. As long as you stay in the current encoding or move from a "small" encoding to a "big" encoding you are safe. If possible, then this is the desirable solution.
- Use transliteration: This means mapping from one encoding to another. This can be achieved by replacing unknown characters with something similar or a special mark. So "Petr Čech" could become "Petr Cech" or "Petr ?ech". Depending on your use case one or another might be more appropriate.
The new problems
I told you... both solutions might cause troubles.
If the consumer of your output can not deal with UTF-8, then this is not an option. It would just move the problem out of your sight (which might be good enough ;-))
If you have changed the name of "Petr Čech" to "Petr Cech" and later on this data is imported again into another system, then it might or might not match up. I.e. If the other system is looking for user "Cech" but only knows about a user "Čech".
Also then transliteration (in our case) is irreversible. There is no way of going back to the original form.
Summary
If possible then stay within one encoding from input to processing to output. In my experience you’ll have fewer problems if you chose UTF-8 as it can cover a wide range of foreign languages, unlike ASCII, CP1252, ISO-8859-1.
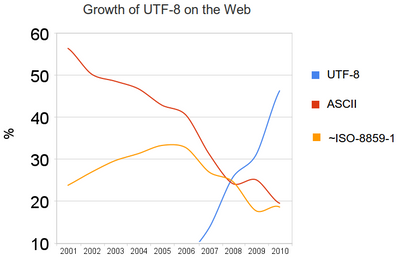
According to this Graph (source) UTF-8 is used more and more on the web. Hopefully one day we don't have to think about ISO-8859-1 anymore.
I recently had to write custom rake tasks for a Rails project which deals with multiple databases (one Rails database and 1+ additional databases). The way we deal with multiple databases should be covered in another post. Now i only want to show the difference between invoke and execute.
invoke
Rake::Task[:a_task].invoke
Only runs the task if needed. Which in our case translates to once.
execute
Rake::Task[:a_task].execute
Runs the task as many times as called.
